Flow as robotic manipulation interface
a reliable method
Flow as robotic manipulation interface
Overview
Cross-embodiment and cross-environment domain gaps pose significant challenges for generalized manipulation in robotics. Users often need to retrain models repeatedly due to differences in embodiments and environments. However, what if we could use an interface that remains invariant to embodiment and environment? Researchers have explored various solutions, one of which involves using trajectories of end-effector positions or manipulated objects. This paper presents an example of this approach.
Method
part1: image to flow
The primary challenge lies in representing and generating the flow. While it is straightforward to represent the flow using a sequence of Euclidean coordinates, generating the flow is more complex. The method proposed by the researchers is illustrated in the figure below: 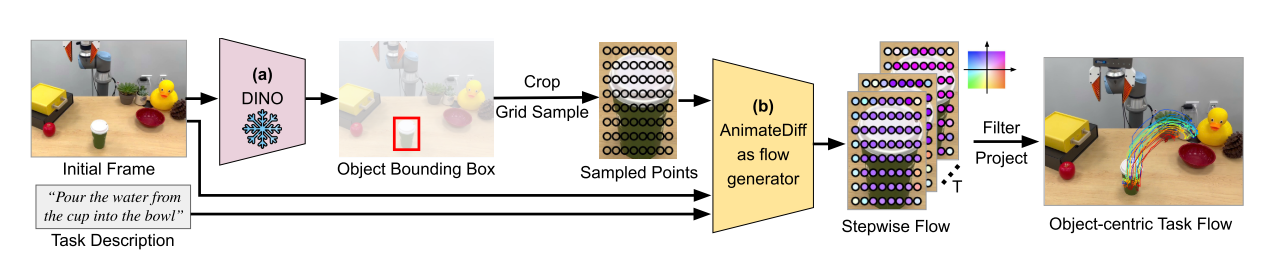 First, Grounding DINO is employed to locate the target objects specified in the textual prompt, returning a bounding box. Next, keypoints are sampled uniformly within the bounding boxes. During model training, a point tracker called TAPIR is used to obtain flow data with temporal steps from the given video. This data is then used to train a diffusion-based model to predict and generate flow. Finally, the flows are postprocessed using a motion filter to mask out unnecessary points
part2: flow to action
Another challenge is generating actions based on the flow. In this paper, researchers train an imitation learning policy to output action sequences based on the generated flow, state, and proprioception. The state refers to the locations of keypoints. The flow-conditioned imitation learning policy consists of three components: - state encoder - temperal alignment module - a diffusion action head
state encoder
The state encoder is a transformer-based network. Its input consists of N keypoints (i.e., the points after motion filtering) along with their 3D coordinates. The output is a representation of the current state.
Temperal alignment
This module enables the embodiment/policy to understand the current state. It takes the entire flow, current state, and proprioception as input and outputs the remaining flow in latent space.
diffusion head
This module generates actions conditioned on the flow, state, and proprioception. It is clear, however, that the method is not as generalized as initially expected.
Summary
In my opinion, the advantage of this method compared to ATM and General Flow is its ability to generate descriptions for the entire motion rather than just the next-step motion. It performs reliably when tested on in-domain tasks. However, the imitation learning policy for converting flow to action is not embodiment-invariant. Therefore, the method is not fully generalized when considered in an end-to-end manner.
Reference
This post is licensed under CC BY 4.0 by the author.